내가 원하는 스타일로 AI 애니메이션을 만들 수 있다면?
기성 LoRA를 넘어, 나만의 스타일을 직접 학습하다
안녕하세요. Toonkit 개발팀입니다.
Toonkit으로 여러 컷을 생성하다 보면 한 가지 불편함을 느끼셨던 분들이 있을 겁니다. 분명 같은 프로젝트 안에서 만든 이미지인데, 컷마다 선화나 색감이 조금씩 달라 보이는 문제입니다. 프롬프트를 아무리 정교하게 써도, 컷이 늘어날수록 스타일이 흔들리는 건 일반 이미지 생성 모델의 구조적인 한계이기도 합니다. 이 문제를 해결하기 위해 저희가 준비한 것이 ToonXL이었고, 거기서 한 걸음 더 나아간 이야기를 오늘 하려 합니다.
1. ToonXL로도 해결되지 않는 문제가 있었습니다
ToonXL은 특정 애니메이션 스타일을 학습한 LoRA를 기반으로, 여러 컷에서도 일관된 그림체가 유지되도록 설계한 모델입니다. 팀이 직접 선별한 스타일로는 꽤 안정적인 결과를 보여줬습니다.
하지만 문제는 여기서 생겼습니다. "팀이 제공하는 스타일" 바깥에서였습니다. 유저마다 원하는 스타일은 제각각이고, 모든 스타일을 팀이 미리 준비해두는 건 현실적으로 불가능했습니다. 결국 ToonXL은 좋은 출발점이었지만, 유저 각자가 원하는 세계관을 표현하기엔 여전히 한계가 있었습니다.
2. ComfyUI, LoRA 공유 플랫폼… 근데 내가 원하는 스타일이 없다면?
ComfyUI나 Civitai 같은 플랫폼에서는 이미 수많은 LoRA를 무료로 받아 쓸 수 있습니다. 지브리풍, 특정 웹툰 스타일, 수채화 느낌 등 잘 만들어진 LoRA들이 공유되어 있고, 이를 활용하면 스타일 일관성 문제를 어느 정도 해결할 수 있습니다.
하지만 이 방법에는 분명한 한계가 있습니다. 누군가 만들어둔 스타일 중에서 "고르는" 것이지, 내가 원하는 스타일을 "만드는" 것이 아니기 때문입니다. 기성 스타일과 미묘하게 다른 나만의 세계관, 혹은 아직 아무도 LoRA로 만들지 않은 스타일을 원한다면 결국 직접 학습 외에는 방법이 없습니다.
3. 결국 필요한 건 "내 스타일을 직접 학습하는 기능"
그래서 다음 질문은 자연스럽게 이어졌습니다. "유저가 직접 원하는 스타일을 가르칠 수 있다면 어떨까?" 자신이 원하는 그림체의 이미지를 제공하면, 그 스타일을 학습한 LoRA가 생성되고, 이후 컷 생성에 그 LoRA가 적용되는 흐름입니다. 팀이 제공하는 스타일의 한계를 넘어, 유저 각자가 원하는 세계관을 직접 만들 수 있게 되는 셈입니다.
4. 현재 Toonkit의 스타일 학습, 어디까지 왔나
현재 Toonkit에서 유저가 직접 스타일을 학습할 수 있는 기능을 제공하고 있습니다. 다만 아직은 몇 가지 제약이 있습니다.
우선 학습에 사용할 수 있는 베이스 모델의 선택지가 사실상 하나로 제한되어 있습니다. 더 다양한 베이스 모델에서 학습을 지원하고 싶지만, 안정적인 품질을 보장하면서 서빙할 수 있는 환경을 먼저 갖추는 것을 우선으로 했습니다.
또한 퀄리티 있는 결과를 얻으려면 유저가 최소 20장 이상의 이미지를 준비해야 합니다. 이미지가 적으면 스타일이 제대로 학습되지 않거나, 컷마다 결과가 불안정해지는 문제가 생깁니다. 학습 데이터의 양과 품질이 결과에 직접적인 영향을 주기 때문에, 현재는 이 기준을 권장하고 있습니다.
5. AWS Batch로 학습 파이프라인을 서빙하기까지
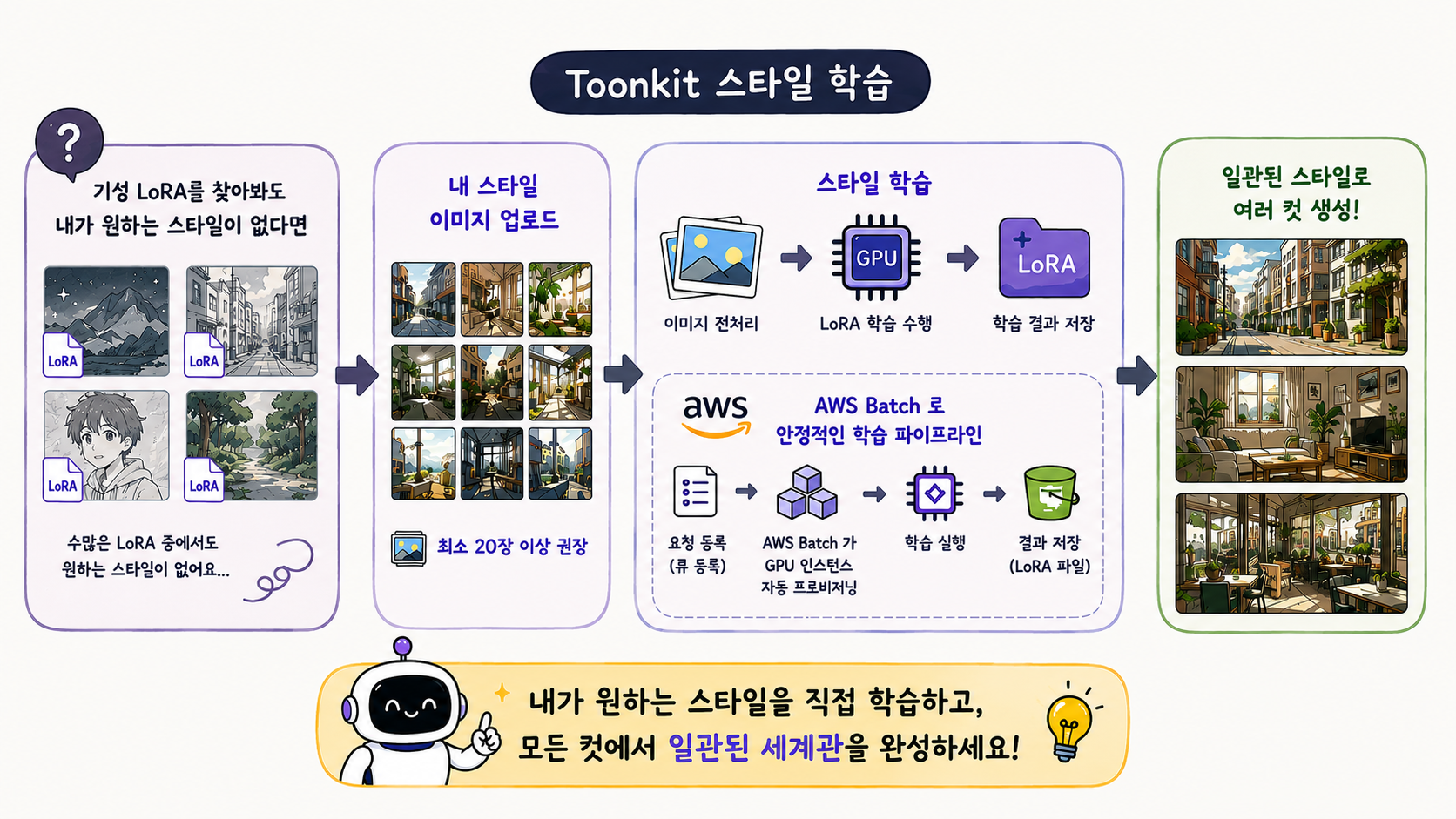
유저가 이미지를 업로드하면 전처리, 학습 실행, 결과 저장까지 전 과정이 자동으로 이루어져야 합니다. 여러 유저의 요청을 동시에, 안정적으로 처리하기 위해 저희는 AWS Batch를 선택했습니다.
유저가 학습을 요청하면 작업이 큐에 등록되고, AWS Batch가 GPU 인스턴스를 자동으로 프로비저닝해 학습을 실행한 뒤 완료되면 결과를 저장하는 구조입니다. 항상 GPU를 띄워두지 않아도 되기 때문에 비용 효율적이고, 요청이 한꺼번에 몰려도 큐로 순차 처리가 가능해 안정성도 확보할 수 있었습니다.
6. 앞으로의 방향
현재는 베이스 모델의 선택지가 제한적이지만, 앞으로 지원 모델의 범위를 점차 넓혀갈 예정입니다. 더 다양한 베이스 모델에서 학습이 가능해질수록, 유저가 표현할 수 있는 스타일의 폭도 함께 넓어질 것입니다.
또한 지금은 퀄리티 있는 결과를 위해 20장 이상의 이미지가 필요하지만, 더 적은 데이터로도 안정적인 학습이 가능하도록 파이프라인을 계속 개선해나갈 계획입니다. 언젠가는 몇 장의 이미지만으로도 나만의 스타일을 Toonkit에 담을 수 있게 되는 것, 그게 저희가 가고자 하는 방향입니다.