What If You Could Create AI Animations in Your Own Style?
Beyond Pretrained LoRAs: Train Your Own Style
Hello, we're the Toonkit development team.
If you've been using Toonkit to generate multiple cuts, you may have noticed something frustrating: even within the same project, the linework or color tone can shift slightly from cut to cut. No matter how carefully you write your prompts, the style tends to drift as the number of cuts increases — and that's partly a structural limitation of general-purpose image generation models. ToonXL was our answer to this problem, but today we want to talk about the step we took beyond that.
1. There Were Problems ToonXL Couldn't Solve
ToonXL is a style-specialized model built on a LoRA trained for specific animation styles, designed to keep a consistent look across multiple cuts. For the styles our team curated directly, the results were quite stable.
But the problem emerged outside of those "team-provided styles." Every user has a different style in mind, and it's simply not realistic for the team to prepare every possible style in advance. ToonXL was a good starting point, but it still had limits when it came to letting each user express their own unique visual world.
2. ComfyUI, LoRA Sharing Platforms… But What If Your Style Isn't There?
Platforms like ComfyUI and Civitai offer a vast library of LoRAs available for free. From Ghibli-inspired styles to specific webtoon looks to watercolor aesthetics — there are many well-crafted LoRAs to choose from, and using them can go a long way toward solving the style consistency problem.
But there's a clear limitation here. You're choosing from styles someone else made — not creating the style you actually want. If you have a vision that's subtly different from anything available, or a style that no one has turned into a LoRA yet, there's ultimately no option but to train it yourself.
3. What's Really Needed: The Ability to Train Your Own Style
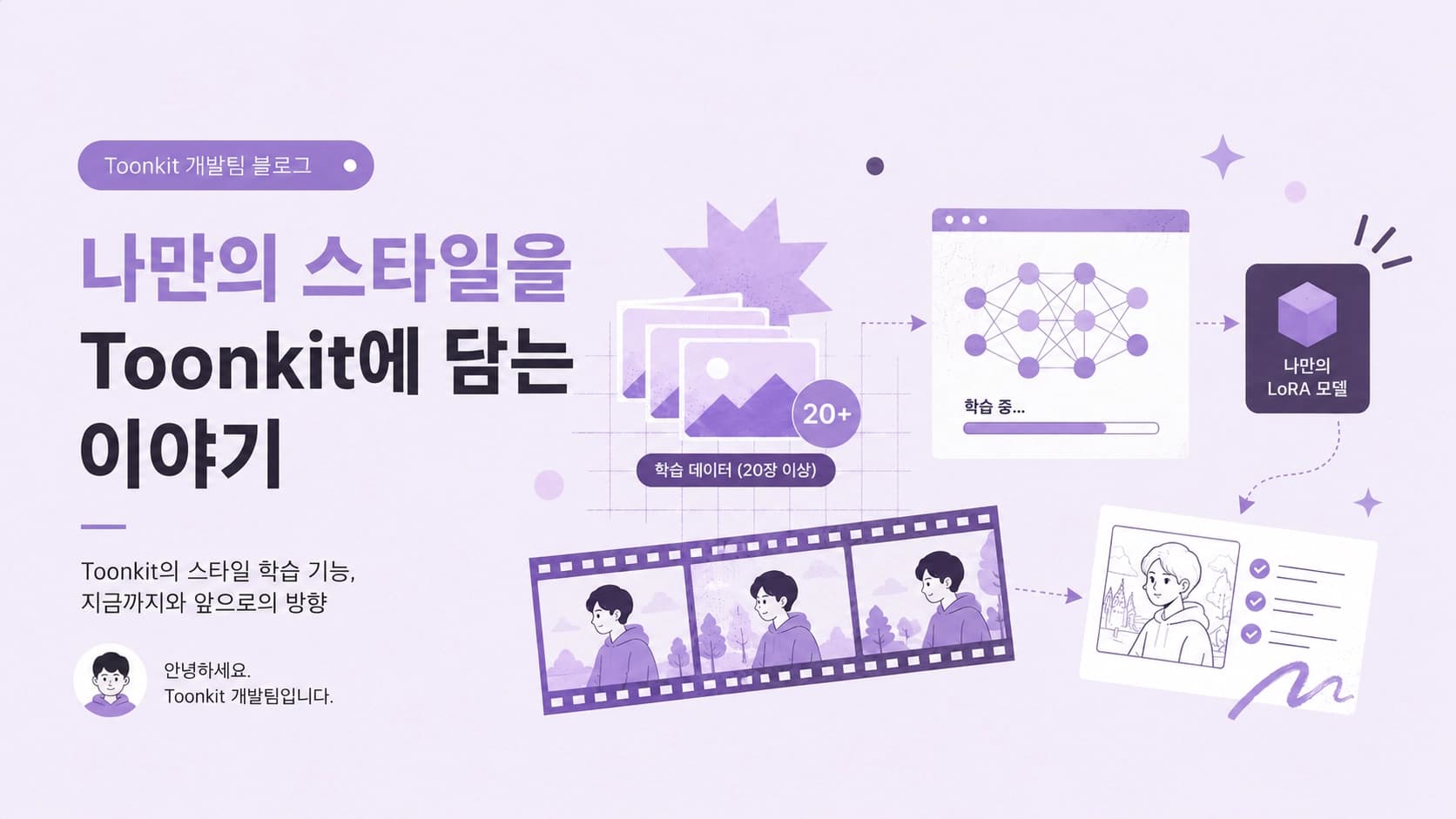
That naturally led to the next question: "What if users could teach the model their own style directly?" The idea is simple — you provide a set of images in the style you want, a LoRA is trained on that data, and that LoRA is then applied when generating your cuts. It means moving beyond the limits of what the team provides, and giving each user the power to build their own visual world.
4. Where Toonkit's Style Training Stands Today
Toonkit now offers a feature that lets users train their own style directly. That said, there are still some constraints at this stage.
For one, the choice of base model for training is currently limited to essentially one option. We'd love to support a wider range of base models, but our priority has been to first establish a stable, reliable serving environment that can guarantee consistent quality.
Additionally, getting quality results currently requires users to prepare at least 20 images. With fewer images, the style may not be learned properly, or the results can become inconsistent across cuts. Since the quantity and quality of training data directly affects the output, we recommend this as the minimum threshold for now.
5. Building the Training Pipeline on AWS Batch
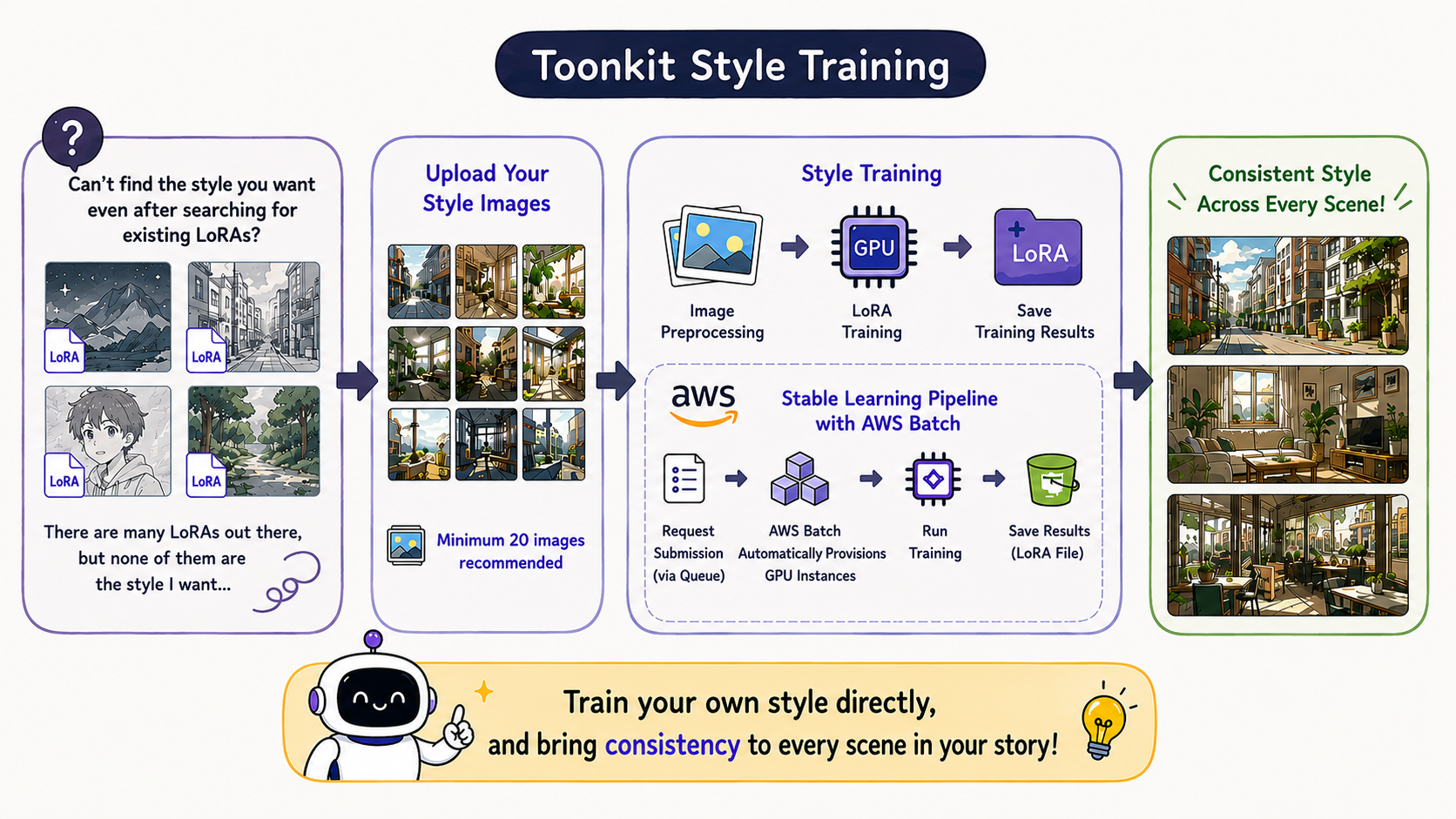
Once a user uploads their images, the entire process — preprocessing, training, and storing the resulting LoRA — needs to happen automatically. To handle multiple users' training requests simultaneously and reliably, we chose AWS Batch.
When a user submits a training request, the job is added to a queue. AWS Batch then automatically provisions a GPU instance, runs the training job, and stores the result when it's done. Because GPU instances don't need to stay running at all times, the approach is cost-efficient. And since requests are processed sequentially through the queue even during traffic spikes, we're also able to ensure stability.
6. What's Next
Right now, the choice of base model is limited — but we plan to gradually expand the range of supported models. As more base models become available for training, the variety of styles users can express will grow alongside them.
We're also working to reduce the data requirement. Currently, 20 or more images are needed for reliable results, but we're continuously improving the pipeline to make quality training possible with fewer images. The goal is a future where just a handful of images is enough to teach Toonkit your own style — and that's the direction we're heading.